1、 首先,安装bs4模块,该模块包含BeautifulSoup库。Windows下进入dos中,敲入以下命令:>>>pip install bs4本机已经安装成功,因此图片可能有些区别。如果没有安装pip,可以先去安装,具体自己查询。


2、>>>python敲入命令回车进入Python交互模式,敲入以下命令>>>from bs4 import BeautifulSoup导入BeautifulSoup库,回车倒入成功。

3、>>>from urllib.request import urlopen>>>html = urlopen("https://baike.baidu.com/")>>>bsObj = BeautifulSoup(html.read())图中表示网页的内容已经转化为了BeautifulSoup对象。
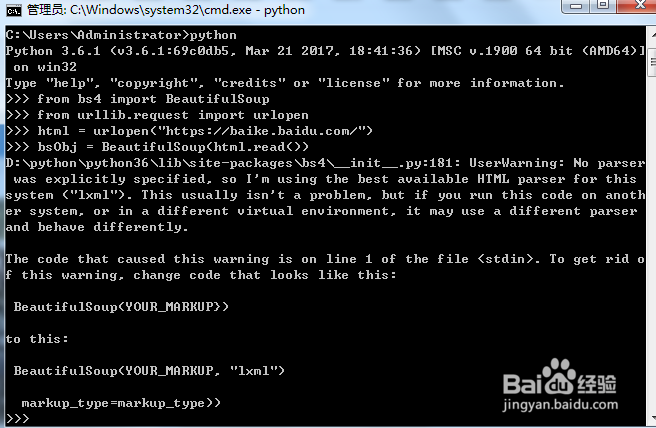
4、>>>bsObj.div.a从网页中提取第一个div中的<a>标签成功>>>bsObj显示网页内容。